03/09/2018 Разработчики из Facebook научили машинный перевод обходиться без параллельных корпусов
Впервые опубликовано на сайте издания N+1
На сайте издания N+1 была опубликована заметка о новой системе машинного перевода ![]() .
.
Ниже материалы заметки приведены полностью.
Разработчики из Facebook представили новую систему машинного перевода, которая обходится без параллельных корпусов.
Обучаясь словарю на векторных представлениях слов, и грамматической правильности - на несвязанных отрывках текста, система показывает эффективность и правильность перевода выше, чем все другие используемые сейчас подходы. Препринт статьи выложен на arXiv, коротко о работе сообщается на сайте компании.
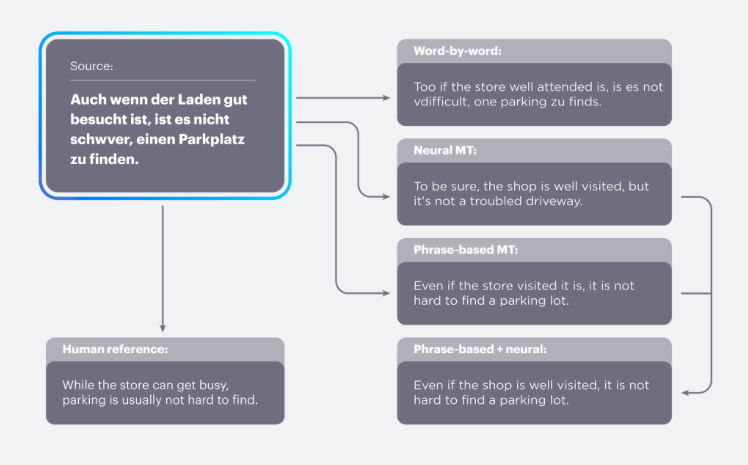
Для машинного перевода обычно требуется достаточно объёмный параллельный корпус - сборник текстов на языке-источнике и целевом языке. Такой классический подход к машинному переводу ещё называют статистическим, а использование в дополнение к нему глубокого обучения также позволяет повысить точность выполнения задачи. К примеру, гибридную систему перевода год назад представил Яндекс.Переводчик.
Несмотря на то, что в последние годы в решении задач машинного перевода удалось добиться больших успехов, до сих пор остаётся одна существенная проблема: машинный перевод эффективен только в том случае, если и для языка-источника, и для целевого языка есть достаточное количество текстовых фрагментов. Решением подобного ограничения может быть использование обучения без учителя, которое не требует большого количества ресурсов. Опробовать этот подход для машинного перевода с ограниченным количеством данных обучающей выборки решили разработчики из Facebook под руководством Гийома Лампля.
Их система сначала учит векторные представления каждого слова на определённом языке. Все слова языка можно представить в виде вектора в многомерном пространстве и таким образом подробно изучить их семантику: к примеру, в таком пространстве слово «кот» будет ближе к слову «животное» и слову «кошечка», чем к слову «ракета» или «молекула». Такой подход работает для любого языка и, имея векторное представление слов языка-источника и целевого языка, можно совместить два пространства: координаты одинаковых слов (к примеру, «кошка», «cat» и «gatto») в них будут совпадать. Система, таким образом, может выучить целый словарь-переводчик, не имея для обучения пар слов на двух языках.
Для перевода целых текстов, однако, такой подход работает плохо: в первую очередь, из-за того, что грамматические параметры могут не учитываться. Разработчики решили эту проблему, обучив нейросеть правильным языковым моделям: рассматривая примеры на языке, система учится наиболее грамматически корректным языковым формам и сочетаниям. Зная, таким образом, перевод отдельных слов и правильную структуру предложений на исходном и целевом языке, система машинного перевода может выдавать корректный перевод. На третьем шаге система улучшает собственный машинный перевод, сравнивая его с грамматически правильными формами сочетаний.
Полученную систему проверили на парах перевода с французского и немецкого на английский и оценили её эффективность с помощью алгоритма оценки машинного перевода BLEU (bilingual evaluation understudy). Обычно коэффициент BLEU - число от 0 до 1, но в своей работе исследователи оценивали качество по шкале от 0 до 100: им удалось добиться повышения качества перевода на 10 баллов по сравнению с методиками, разработанными ранее.
Новая система позволит обходиться без параллельных корпусов, подготовленных лингвистами. Это преимущество для редких языков, где данных для обучения систем машинного перевода может не хватать. Новый алгоритм перевода сможет решить эту проблему: тем не менее, разработчики уточняют, что их систему ещё надо улучшить.
Векторное представление слов также эффективно используется для изучения социальной динамики на основе текста. К примеру, весной 2018 года американские учёные с помощью этого подхода смогли отследить, как в течение прошлого века менялось отношение людей к женщинам и азиатам.
© Елизавета Ивтушок
Впервые опубликовано на сайте издания N+1
хостинг для сайтов © Langust Agency 1999-2024, ссылка на сайт обязательна
