01/08/2019 Translate-баттл: могут ли онлайн-переводчики передавать стиль текста?
Впервые опубликовано на сайте «Системный Блокъ»
На сайте «Системный Блокъ» была опубликована статья о качестве машинного перевода.
Ниже материалы статьи приведены полностью.
«Мой мозг застрял в черепе», «He was introduced to the wells», «филиал исследований» и другие приключения онлайн-перевода
Фраза «Старый добрый Гугл-транслейт» уже стала поговоркой XXI века. При этом люди необязательно говорят именно об американской технологии: многие пользуются переводчиком от Яндекса, а кое-кто искренне уверен, что лучше сервиса PROMT ![]() ничего не найти. Машинный перевод умнеет на глазах: сейчас мы читаем осмысленные тексты там, где ещё месяц назад был набор словосочетаний, плохо поддающийся пониманию. Однако есть один аспект, который относится не столько к тому, ЧТО написано, сколько к тому, КАК это сделано. Стиль изложения уникален для каждого текста, особенно в художественной и публицистической литературе. Понимают ли эти особенности онлайн-переводчики? Посмотрим на примере сервисов Google Translate, PROMT RBMT, Systran и Яндекс.Переводчик.
ничего не найти. Машинный перевод умнеет на глазах: сейчас мы читаем осмысленные тексты там, где ещё месяц назад был набор словосочетаний, плохо поддающийся пониманию. Однако есть один аспект, который относится не столько к тому, ЧТО написано, сколько к тому, КАК это сделано. Стиль изложения уникален для каждого текста, особенно в художественной и публицистической литературе. Понимают ли эти особенности онлайн-переводчики? Посмотрим на примере сервисов Google Translate, PROMT RBMT, Systran и Яндекс.Переводчик.
Немного теории
Виды машинного перевода
Как мы уже знаем, существует два основных подхода, которые лежат в основе технологии машинного перевода. Первый подход основан на правилах (англ. rule-based), второй - на статистике (англ. statistical-based).
Перевод на основе правил подразумевает использование словаря и грамматики языка-оригинала и языка перевода. Точность перевода по правилам зависит от полноты данных используемых словарей.
Статистический машинный перевод на сегодняшний день является доминирующим.
Принцип его работы заключается в следующем: в память системы загружается большое количество параллельных текстов (то есть тексты с одной и той же информацией, написанной на разных языках), которые в дальнейшем будут являться основой для перевода. Статистическая модель разбирает входные предложения на слова и фразы, перебирает все варианты перевода и оценивает вероятность каждого из них, после чего составляет несколько вариантов перевода предложения целиком и выбирает в качестве результата вариант, в котором фрагменты обладают наибольшим вероятностным весом.
В последние годы практически все сервисы машинного перевода стали использовать так называемый гибридный принцип работы, поскольку теперь работу поддерживают обучаемые нейронные сети.
Оценка
Когда мы получаем онлайн-перевод нужного нам текста, то сразу можем сказать, хороший он или плохой. Но экспертам и разработчикам онлайн-сервисов машинного перевода нужны более чёткие критерии оценки, поскольку так они смогут увидеть, в каких аспектах тот или иной сервис «слабоват» и что можно сделать, чтобы его улучшить.
В современном переводоведении машинный перевод можно оценить ручным и автоматическим способами. Разработкой ручной оценки занимался Макото Нагао, который предложил оценивать машинный перевод, основываясь на лингвостилистическом анализе.
Так, шкала оценивания содержит от пяти до одного баллов: перевод получает 1 балл, если понятен смысл предложения, грамматика и стиль не требуют постредактирования; 2 балла ставится, если смысл предложения понятен, но возникают большие проблемы с грамматикой, лексическим наполнением и стилем; 3 балла перевод заслуживает, если понятен общий смысл предложения, но некоторые его части вызывают сомнение ввиду неправильного грамматического строя; при наличии ошибок словоупотребления и стилистики выставляется 4 балла; если же в предложении имеется большое количество грамматических, лексических и стилистических ошибок, смысл предложения с трудом понимается даже после внимательного изучения, перевод оценивается в 5 баллов.
В сравнении с ручным методом автоматическая оценка перевода предполагает очевидные плюсы использования: прежде всего она значительно дешевле, чем проверка экспертами, а кроме того предполагает максимальную объективность оценивания, что весьма труднодостижимо в работе человека.
Самым используемым способом автоматической оценки является эталонное сравнение: для текстового корпуса экспертами подготавливаются образцы, с которыми потом и сравнивают переведённые тексты. Сравнение проводится на основе метрик, набор которых весьма велик. Самыми известными метриками являются BLEU, а также её надстройки METEOR, NIST и WER. Они работают с N-граммами - последовательностями из n-элементов, которые могут быть представлены звуками, буквами, слогами или словами.
Самой распространённой является программа BLEU. Как мы помним, у этой метрики есть существенный недостаток: она может недостаточно высоко оценить перевод только из-за несовпадения количества слов в структуре или другого, хотя и уместного выбора слов.
Для преодоления недостатков BLEU разработчики создали метрику METEOR, в которой за единицу оценки принимается слово, а также допускается перифраз в тексте перевода и учитывается изменение слов флективным способом. Это позволяет метрике немного приблизиться к качеству ручной оценки машинного перевода. Как надстройка к BLEU была разработана и метрика NIST. Она также вычисляет количество повторения n-грамм, оценивая полноту и точность текста, но при этом придаёт больший вес редким n-граммам и определяет степень информативности в повторяющихся n-граммах. Метрика Word Error Rate (WER) изначально использовалась для оценки работоспособности систем по распознаванию речи, но позже была адаптирована и для работы с машинным переводом. Чтобы с помощью WER получить оценку перевода, необходимо сложить все вставки, удаления и замены, сделанные относительно эталонных предложений, и разделить сумму на длину эталонного предложения. Перевод тем лучше, чем ниже значение WER.
Метрики автоматической оценки сейчас достаточно популярны, однако их существенный недостаток заключается в том, что полученный результат не может быть полностью адекватным, поскольку при такой оценке не ставится задача понимания семантики и стилистики текста, а это может привести к весьма неточному конечному результату.
У всех этих способов оценки есть один большой минус: в них уделяется внимание скорее грамматической стороне текста перевода, в то время как тексты мы различаем благодаря стилю, в котором они написаны. В романе, деловом письме или научно-популярной статье предложения будут написаны по одним грамматическим правилам, но стиль не позволит нам назвать статью романом. И это самая слабая на сегодняшний день сторона машинного перевода. Именно поэтому имеет смысл рассмотреть возможности популярных онлайн-переводчиков по сохранению стилистических особенностей текстов оригинала.
Много практики
Отбор материала
Для этого небольшого эксперимента было решено рассмотреть тексты 4 основных функциональных стилей: художественного, научного, официально-делового и публицистического. Для отбора использовался метод свободной выборки, и результатом стал следующий список фрагментов текстов в языковой паре русский-английский:
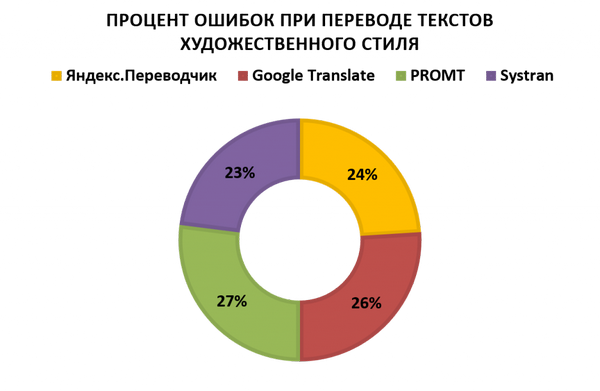
Художественный стиль - роман «Атлант расправил плечи»
 , пьесу «Чайка» и сонет У. Шекспира № 119 ;
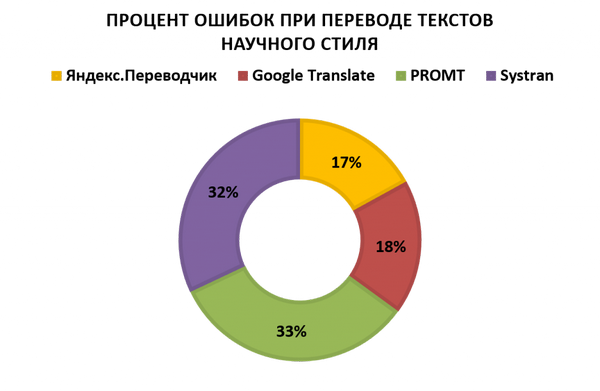
, пьесу «Чайка» и сонет У. Шекспира № 119 ;Научный стиль - аннотация к статье «Языковые реалии и национальная языковая картина мира в произведениях Ч. Диккенса»
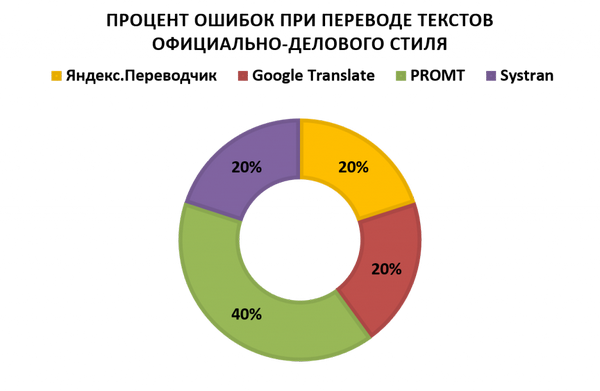
, научная статья «Sleep more in Seattle: Later school start times are associated with more sleep and better performance in high school students» и научно-популярная статья «На каких языках нужно говорить, если хочешь повлиять на мир?»;Официально-деловой стиль - Заявление официального представителя Министерства иностранных дел России Александра Яковенко, Договор на оказание услуг платного образования (НИЯУ «МИФИ») и письмо от службы поддержки онлайн-переводчика SYSTRAN;
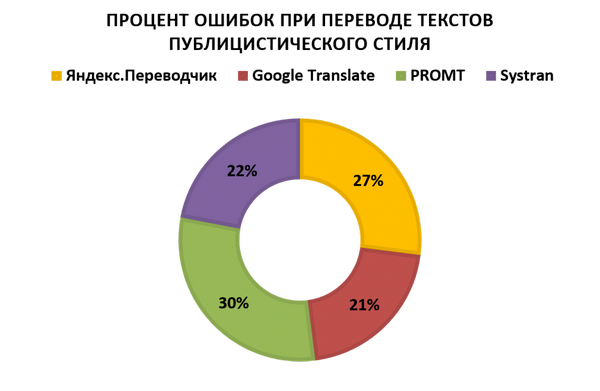
Публицистический стиль - эссе О. Уайльда «Истина о масках»
и статьи «Как заработать миллиард долларов на чайном грибе» и «Uber IPO: Here's Who Stood To Get Big Payouts».
Для каждого жанра были определены стилистические особенности, нарушение которых предполагается классифицировать как ту или иную стилистическую ошибку. Таким образом, общими особенностями для изучаемых текстовых стилей становятся:
Для художественного стиля:
многозначность лексических единиц;
экспрессивность выражения («мне, брат, в деревне как-то не того»);
образность высказывания («out of dying wells»);
инверсия, синтаксический параллелизм («the heart had started pumping, the black blood had burst»).
Для научного стиля:
строгое следование терминологии («лакуны», «Т-критерий Уилкоксона»);
использование аббревиатур, формул, специальных знаков («ANOVA», «F(143.25.025) = 2.19»);
объективность высказывания;
прямой порядок слов («Figure 1A presents the wrist activity…»).
Для официально-делового стиля:
языковой стандарт для каждого типа текста;
точность формулировок;
использование клише, устойчивых вводных конструкций, канцеляризмов («акт сдачи-приёмки», «Best regards»);
преобладание сложных предложений.
Для публицистического стиля:
использование книжной и разговорной лексики в одном тексте («to nab a coveted spot», «flawless chiseled cheekbones»);
употребление восклицательных предложений и риторических вопросов («…for the image of Ancient Rome!»);
субъективность высказывания («We look to the archaeologist for the materials…»).
Ошибки, соответственно, представляют из себя:
В художественном стиле:
нарушение экспрессивности выражения («it doesn't suit me» - ошибка: «мне не подходит», правильно: «как-то не того»);
прямой перевод вместо описательного («Ему представились скважины» - ошибка: «He was introduced to the wells», правильно: «He thought of the wells»);
нарушение синтаксиса как стилистического приёма (ошибка: «and it began to beat in a new way, chasing black blood», правильно: «the heart had started pumping, the black blood had burst»);
нарушение оформления текста (искажение/отсутствие авторских ремарок в пьесе - «[Смеётся]»).
В научном стиле:
неверный перевод терминов («new branch of linguistics» - ошибка: «филиал», правильно: «отрасли исследования»);
нарушение нейтральности высказывания («a clear difference» - ошибка: «чёткая разница», правильно:«очевидное различие»);
ошибки в написании формул, аббревиатур (ошибка: «<», правильно:«< (меньше)»);
нарушения в адаптации текста под широкую публику (в научно-популярной статье - ошибка: «However», правильно: «but»).
В официально-деловом стиле:
неверный перевод канцеляризмов и клише (ошибка: «Контракт для услуг», правильно: «Договор на оказание услуг»);
нарушение структуры устойчивых конструкций (ошибка: «МИФИ», правильно: «Федеральное государственное автономное образовательное учреждение высшего образования «МИФИ»);
снижение лексики (ошибка: «большая восьмёрка», правильно: «группа восьми»);
нарушения в организации текста (для текстов договора и делового письма).
В публицистическом стиле:
неверное оформление риторических вопросов и восклицаний;
нейтрализация субъективности высказывания;
нейтрализация эмоционально-оценочной лексики (ошибка: «to win a rightful place», правильно: «to nab a coveted spot»);
снижение лексики (ошибка: «to imagine», правильно: «to contemplate»).
Анализ переводов
Для начала были найдены экспертные (выполненные профессионалами) переводы текстов, отобранных для исследования. Затем они были снова переведены сервисами онлайн-перевода на язык оригинала, и полученный перевод сопоставлялся со своей первоначальной версией, например:
Оригинал:
«The network maps show what is already widely known: If you want to get your ideas out, you can reach a lot of people through the English language. But the maps also show how speakers in disparate languages benefit from being indirectly linked through hub languages large and small. On Twitter, for example, ideas in Filipino can theoretically move to the Korean-speaking sphere through Malay, whereas the most likely path for ideas to go from Turkish to Malayalam (spoken in India by 35 million people) is through English. These networks are revealed in detail at the study's website».
Вариант переводчика PROMT:
«Sometimes networks tell us already widely known facts. For example, not news (грам) that if you want that you were heard (пр.пер), you should use English.(стил) However they also show that carriers of the most different languages sometimes are the indirectly bound through nodal (нев.в) languages -(пункт) large and shallow (нев.в). Let's tell (стил!), into (грам) Twitter the idea stated on (грам)-fillipinski theoretically can pass in koreeyazychny (непер) users in the Malayan (грам), and the most probable way from Turkish to Malayalam (language which in India 35 million people speak (синт)) lies (нев.в) through English. More information can be got (стил) about networks on the research website».
Теперь осталось произвести подсчёт ошибок согласно классификации, составленной ранее на основе жанровых особенностей текстов.
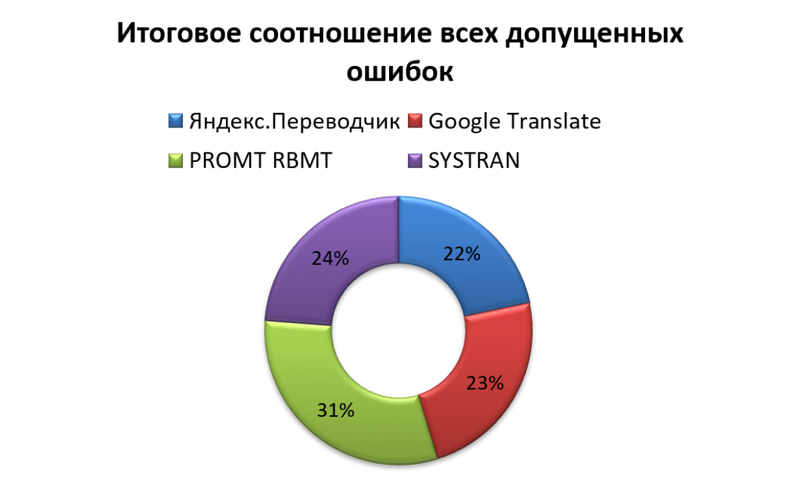
Мы видим, что ни один исследуемый онлайн-сервис не способен на данный момент выполнить перевод, не потеряв в процессе большую часть стилистических особенностей исходного текста. В общей сложности онлайн-переводчики допустили 673 стилистические ошибки, из которых 208 ошибок было допущено сервисом онлайн-перевода PROMT RBMT, 160 сервисом SYSTRAN, 159 сервисом Google и 146 сервисом Яндекс. Есть и хорошие новости: иногда сервисам онлайн-перевода удаётся подобрать перевод, полностью совпадающий с оригинальным текстом, хотя эти случаи на данный момент - исключение из правил.
Что делать?
Пока что единственное, что могут сделать обычные пользователи - исправлять текст непосредственно в окне перевода, а затем использовать по своему усмотрению. Так системы будут накапливать возможные комбинации слов и их сочетаний, и процесс улучшения качества перевода ускорится. Эта функция доступна у Яндекса и Google. К сожалению, PROMT и SYSTRAN такой возможности не предоставляют.
© Анастасия Гарькуша
Впервые опубликовано на сайте «Системный Блокъ»
хостинг для сайтов © Langust Agency 1999-2024, ссылка на сайт обязательна
